1. Introducción: ¿por qué necesita gestionar el rendimiento?
Todo director de Tecnologías de la Información o responsable de redes sabe que lo que de verdad importa es la productividad que los usuarios puedan obtener de sus sistemas de TI; algo que, a su vez, depende de que toda su infraestructura funcione correctamente. Es posible que cuente con varios métodos estadísticos y de medición de la red y del sistema, pero al final de la jornada los usuarios no tienen ningún interés por ver ese tipo de datos. Lo que de verdad van a percibir es cuál ha sido el rendimiento tecnológico en términos de disponibilidad y rendimiento de la aplicación.
A su vez, cuanto más dispuestas están las compañías a instalar sistemas de VoIP, explorar servicios basados en la nube o consolidar y virtualizar sus centros de datos para ofrecer aplicaciones de forma remota, más obligados se verán los profesionales de las redes a mejorar el rendimiento.
Por tanto, lo que el responsable de redes necesita de verdad saber es el rendimiento de la aplicación, tanto para ayudar a los desarrolladores a entender lo que va a funcionar en una red y localizar las aplicaciones poco funcionales antes de que los usuarios padezcan los efectos, como para ofrecer un rendimiento similar al que ofrecen las redes LAN, pero en la WAN, de forma remota y a centros de trabajo que se encuentran a gran distancia.
Las herramientas de gestión de redes tradicionales no sirven para esto. Fueron diseñadas para hacer un seguimiento de la disponibilidad y los fallos, para enviar mensajes de alerta cuando el servicio o el dispositivo no están disponibles o cuando no se encuentra el umbral predefinido, pero no pueden detectar a tiempo los problemas y las interacciones que se producen en la aplicación.
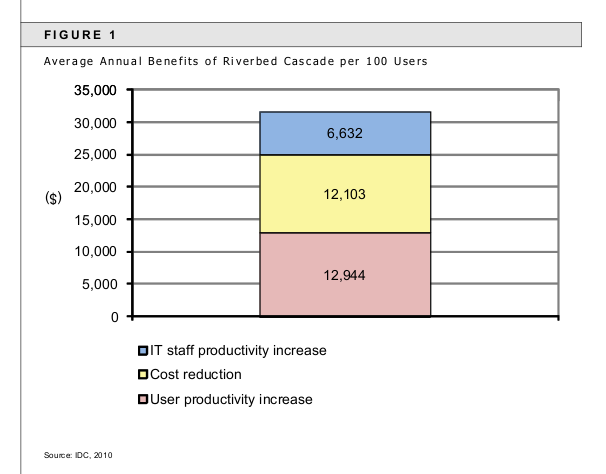
Riverbed Cascade es un tipo de herramienta que incorpora funciones de monitorización del tráfico, captura de paquetes y análisis de protocolo para dar una visión de la red sensible a las aplicaciones. De esta forma podrá ver la ruta de las aplicaciones cuando atraviesan la red, y hará visible a los usuarios su disponibilidad y su capacidad de rendimiento. La creación de este mapa con la ruta de la aplicación en la red y la medición del rendimiento en el camino permite solucionar los problemas actuales, analizar las tendencias y planificar los cambios necesarios en el futuro para la red y para la aplicación.
Recogida y análisis de información en su red
La recogida de datos de la red se ha vuelto más eficiente con la implantación a gran escala de protocolos de flujo para la monitorización del tráfico dentro de los dispositivos de red (como conmutadores y routers). Entre los posibles ejemplos cabe señalar el protocolo NetFlow de Cisco y otros protocolos similares como el estándar IPFIX (Internet Protocol Information eXport), sFlow, etc. Estos protocolos exportan datos de flujo con información sobre el tráfico que registra determinado dispositivo, enviando después estos datos a un dispositivo recolector que los tendrá listos para el análisis.
La información sobre el flujo da una imagen amplia de la red sin necesidad de utilizar muchos recursos. Sin embargo, no contiene información detallada sobre la aplicación, y algunos datos de rendimiento deben recogerse directamente de los paquetes. Con Cascade, obtiene lo mejor de ambos mundos: la información del flujo para tener una visión amplia de la WAN y la recogida de paquetes para métricas más precisas en lugares de la red estratégicos. Toda esta información se incluye en un único conjunto de datos por los que el usuario puede navegar y en el que pueden hacerse búsquedas sin tener que preocuparse de cómo fue recogido un dato en particular.
Incluso así, un simple cálculo para medir el rendimiento de la red es insuficiente: necesita saber cómo y cuándo estas mediciones se desvían de la norma, y esa norma puede incluir ciclos diarios, semanales o incluso de períodos de tiempo más largos. Si no tiene forma de detectar inmediatamente la desviación de la norma, no podrá hacer un seguimiento de la degradación del rendimiento antes de que el servicio caiga y los usuarios se vean afectados.
Gracias al análisis de comportamiento, Cascade realiza esta tarea de forma automática. Calcula las mediciones de rendimiento, como tiempo de respuesta y tasa de transferencia, hace un seguimiento de estas mediciones a través del tiempo (descubriendo de forma automática qué incidencias se producen de forma diaria o semanal) y alerta de cualquier posible desviación del comportamiento normal.
Lo cierto es que los sistemas de análisis de comportamiento asumen las tareas con las que los directores de red tienen que lidiar todos los días (monitorización del tráfico y del consumo de banda ancha) y obtienen un resultado aún mejor, ya que aplican métodos de aprendizaje automático para medir el rendimiento o la ralentización de la aplicación a la hora de solucionar problemas, y detectan amenazas de seguridad. El mejor lugar para ver los problemas de una aplicación es en el momento en el que se produce la transmisión, de otra forma puede ser un verdadero misterio difícil de resolver: en cuanto se sabe cómo leer el tráfico (y esto es precisamente lo que hace Cascade) se sabrá en todo momento lo que está pasando con la aplicación.
Casos reales: Sappi
Sappi necesitaba una solución que monitorizase el rendimiento de sus aplicaciones y solucionase sus problemas. Por eso eligió el cuadro de mandos ejecutivo de Riverbed Cascade. De esta forma, Sappi puede ahora cumplir con los acuerdos sobre el nivel de los servicios (SLA) para aplicaciones de rendimiento y ofrecer a su equipo ejecutivo una manera de hacer el seguimiento. El cuadro de mandos utiliza el código de luces de los semáforos para indicar si los sistemas funcionan adecuadamente (verde) o necesitan ser revisados (naranja y rojo). El equipo de red de Sappi utiliza después Cascade para analizar más en profundidad el problema y resolverlo.
Cascade detecta también el estado de la aplicación y de la red en los cuadros de mando de servicio, de manera que todo el mundo, desde los directivos empresariales hasta los administradores de TI pueden ver los problemas y hacer seguimiento de las brechas que se producen en los acuerdos sobre el nivel de los servicios (SLA). Una vez conocida la existencia del problema, se puede uno centrar en la aplicación, el servidor y el usuario para solucionarlo incluso a nivel del paquete.
La información sobre la red recogida por Cascade es útil no sólo para analizar los problemas presentes, sino también para prevenir los que puedan producirse en el futuro. Puede utilizar la información para descubrir aplicaciones y servidores e identificar las dependencias que se producen en la infraestructura TI, todo a través de una presentación de la información gráfica y sencilla. Esta herramienta puede ser vital para la planificación de proyectos TI de consolidación del servidor, proyectos de virtualización en la nube y otros similares.
Ofrece hasta 1 millón de dólares de compensación económica en caso de incidente, con la…
Este cambio refleja los avances que se producen a nivel de infraestructura TI y el…
El evento espera reunir a 17.000 directivos, que podrán escuchar a medio centenar expertos en…
Como resultado de esta operación, ampliará sus servicios en el "bronze layer" del ciclo de…
Durante el segundo trimestre de su año fiscal 2025 acumuló 1.660 millones de dólares, la…
También incluye un SDK open source para potencia el desarrollo de aplicaciones y agentes, especialmente…
{kind=link}