

En poco tiempo, Facebook superará la barrera de los 1.000 millones de usuarios (en la actualidad se encuentra en torno a los 955 millones, tres veces más que la población estadounidense).
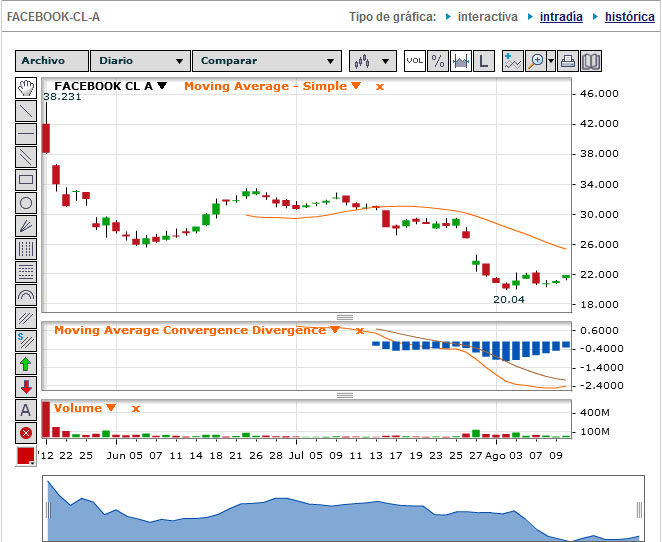
Todo el mundo ha hablado de su salida a bolsa en mayo de este mismo año, en la que el precio por acción se elevó hasta los 42 dólares. Hoy cotiza por debajo de los 22 dólares, prácticamente la mitad de su valor.
Por otra parte, la multinacional GM (General Motors) decidió retirar su publicidad de la red social porque no le era rentable. Que una persona haga clic en el botón “Me gusta” de un determinado producto no significa que vaya a comprarlo.
Un cuarto dato. Se estima que más del 80% de los ingresos actuales de Facebook provienen de la publicidad.
Toda esta información combinada y puesta en perspectiva no parece conducir a nada bueno para la red social más popular. Muchos analistas, de hecho, no han tardado en criticar tal sobreestimación a la hora de salir a bolsa si se tiene en cuenta el pobre impacto que supone la publicidad en la vida de esos cientos de millones de personas que cada día se conectan.
Sin embargo, el verdadero valor de Facebook no se encuentra ni de lejos en la publicidad que es capaz de mostrar, sino en la información que generan sus usuarios a cada segundo que pasa. Aproximadamente, los servidores de la red social almacenan unos 100 PetaBytes (100 millones de GigaBytes), entre fotos, vídeos, comentarios, y demás elementos de comunicación entre los usuarios. Se trata de una cantidad que el año que viene se doblará o incluso triplicará.
Pero, ¿dónde se encuentra almacenado tal volumen de información? Es aquí donde entra en juego la plataforma Apache Hadoop, de la que tantas veces hemos escrito durante los últimos meses. Hadoop no es otra cosa que un entorno capaz de entender y manejar todos esos datos no estructurados (‘Big Data’) de forma independiente al número de servidores en los que estén almacenados. Da igual que se encuentren en un disco duro o en miles de servidores, ya que está diseñado para ser escalable, fiable y distribuido. Y además está basado en código abierto. Toda la información generada en el servicio creado por Mark Zuckerberg está almacenada en este sistema.
Casualidades de la vida, Facebook contribuye desde hace dos años en este proyecto como miembro Gold de la Fundación Apache y dona anualmente 40.000 dólares. No obstante, a pesar de que Hadoop fue creado para facilitar la gestión de grandes volúmenes de datos, los ingenieros de la red social no han sido capaces de adaptar esta plataforma a sus necesidades, que no son otras que facilitar la minería de datos, la posibilidad de estudiar la información en base a determinadas consultas aislándola de las partes que no interesan. Aquí radica el verdadero e incuestionable valor de Facebook. Cuando consiga proporcionar un sistema fiable para analizar la información y facilitar la toma de decisiones en base a dicho análisis, cualquier empresa, negocio u organización pagará por ello.
Y todo ello resguardado en un marco legal que los usuarios aceptan desde el momento en que se dan de alta, ya que no les queda otra que permitir el uso de su información si desean seguir teniendo presencia en la gran red social.
Tarde o temprano, por tanto, conoceremos el verdadero negocio en el que se moverá Facebook: vender al mejor postor los datos que generan los propios usuarios; empaquetados, personalizados y en ‘cajita’ con lazo azul.
Fernando Blázquez, director del Grado en Desarrollo Full-Stack en UDIT, analiza en esta tribuna cómo…
Roberto Alfonso, Country Lead en España de Glintt Next, explica en esta tribuna cómo la…
David Tajuelo, Senior Regional Sales Manager en Cambium Networks Iberia, explica en esta tribuna cómo…
Flor Hernández, Directora General de Atención al Cliente en Servinform, explica en esta tribuna cómo…
Ángel Pineda, CEO de Orizon, explica en esta tribuna cómo la figura del Chief Performance…
En esta tribuna, Matt Roberts, Ansible Platform Lead, EMEA de Red Hat explica cómo la…

