Google ha celebrado esta mañana una jornada llamada ‘The Magic in the Machine’ para dar a conocer sus últimas innovaciones en el ámbito de la inteligencia artificial. El encargado de inaugurar la cita ha sido Jeremiah Harmsen, líder del departamento de Investigación de Google en Europa (Zúrich), quien ha recordado que durante mucho tiempo la Inteligencia Artificil se ha vinculado con los robots, pero no son necesariamente lo mismo. De hecho, hay robots que no utilizan la IA.
Donde realmente se están produciendo las disrupciones dentro de la Inteligencia Artificial es en el campo del Machine Learning o aprendizaje automático. Esta tecnología supone llevar a cabo el entrenamiento de un programa mediante el ejemplo en lugar de instruirlo en líneas de código.
Google ya ha comenzado a introducir el aprendizaje automático en la mayor parte de sus productos principales, aunque no seamos conscientes de ello. En la app de búsquedas el reconocimiento de voz transforma los sonidos en palabras y el procesamiento del lenguaje natural facilita entender lo que se quiere decir. Aproximadamente un 20% de las búsquedas de la aplicación se hacen va a través de la voz.
También está presente en la app de Google Translate al traducir automáticamente en 100 idiomas para hablar, leer o escribir, o en Google Photos, que es capaz de identificar y agrupar los elementos que aparecen en las imágenes. Asimismo, el al aprendizaje automático está detrás de las respuestas Smart Reply que tiene Gmail, para poder responder correos rápidamente, con solo tocar un botón. Y se usa en otros productos de la casa como los sistemas operativos Android Wear y Google Home o el smartphone Pixel.
La empresa de la gran G quiere que esta tendencia -que también le está ayudando a reducir en un 40% la energía usada para enfriar sus centros de datos- esté a disposición de todo el mundo. Por eso, la compañía tecnológica cuenta desde finales de 2015 con TensorFlow, una librería de software open source para Machine Learning. Con TensorFlow cualquier puede codificar sus propios modelos y crear sus propias redes neuronales.
Una red neuronal es un conjunto de algoritmos que se despliegan de forma estructurada los cuales están inspirados en el funcionamiento del cerebro humano. Funcionan usando una entrada de datos determinada y ofreciendo un resultado (en el caso de introducir una foto u objeto puede indicar qué es). Es importante llevar a cabo un entrenamiento para que una red neuronal funcione y aprenda por qué está cometiendo errores con el fin de llegar a resultados cada vez más certeros. Al ir obteniendo más y más ejemplos la red va incrementando su precisión al interpretar los datos. En principio se ofrecen ejemplos etiquetados y más adelante se les dan sin etiquetar para poner a la red neuronal a prueba.
Por lo general existen tres tipos de redes neuronales que pueden combinarse entre sí. Las profundas o de aprendizaje profundo tienen una estructura de ‘pastel’, con múltiples capas superpuestas. Aquí las capas superiores aprenden de las inferiores. El segundo tipo serían las recurrentes, donde hay diferentes nodos conectados entre sí. Estas son muy buenas prediciendo secuencias y se usan mucho para tareas como la interpretación de escritura a mano o el reconocimiento de voz. Por último estarían las convolucionales, que asumen que las entradas de datos son imágenes y limitan su arquitectura a 3 dimensiones.
En un evento en Campus Madrid, Google ha mostrado algunos ejemplos del uso de estas redes. La firma cuenta con una herramienta sintáctica y un grupo de trabajo denominado Magenta, en el que se plantea cómo usar el aprendizaje automático para tareas creativas relacionadas con el mundo del arte o la música. Así se está trabajando en proyectos como Al Duet, donde el sistema responde tocando algunas notas cuando el usuario toca un piano para crear una composición, Quick Draw, que adivina lo que se está dibujando o X Degrees, que es capaz de determinar 6 grados de separación entre dos obras de arte, ofreciendo ‘obras intermedias’.
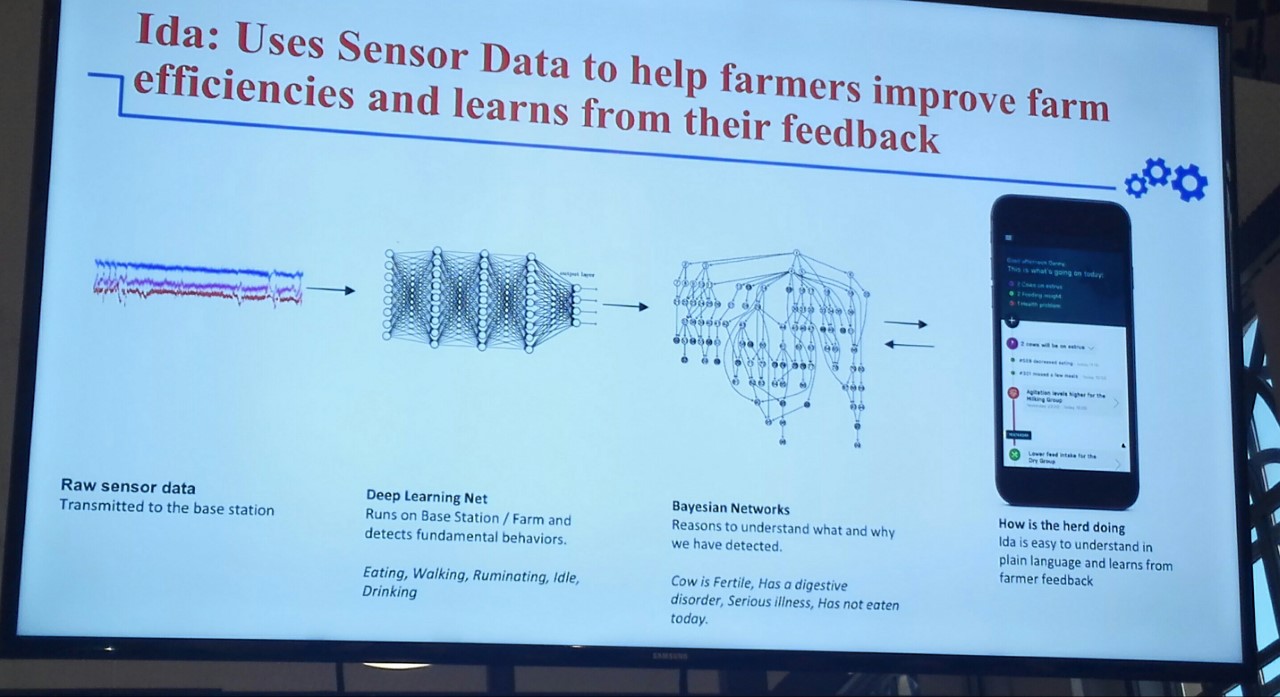
Además, se han mostrado casos de éxito externos, como el de un agricultor japonés que usa el aprendizaje profundo y TensorFlow para clasificar sus pepinos o su aplicación para la búsqueda de leones marinos mediante imágenes. En la jornada se han conocido el uso que hacen empresas como Source (d), que lo están aplicando para contratar programadores ‘compatibles’ con el código con el que cuente una empresa, Connecterra, que es capaz de sensorizar vacas y ofrecer explicaciones sobre qué les ocurre a los granjeros (están enfermas, no han comido, etc), o Wolters Kluwer, la cual está llevando a cabo un proceso de ‘jurimetría’ para monitorizar sentencias, casos, abogados y facilitar toda la información para que los abogados puedan analizar sus posibilidades de éxito en una causa y estar al día en el ámbito de la jurisprudencia.
La apuesta de AWS en España también pasa por facilitar a las administraciones públicas las…
Los sectores mejor pagados, según un estudio de Randstad, son los de ciencia de datos,…
Schneider Electric ha aportado una solución a medida para esta instalación, que facilitará la interconexión…
IDC prevé un incremento del 11,8 % para 2025, impulsado por cuestiones regulatorias, una intensificación…
Los nuevos modelos son: Dell Pro Dock WD25, Dell Pro Smart Dock SD25, Dell Pro…
Diseñada para aplicaciones en servidores como inteligencia artificial, computación de alto rendimiento o servicios en…
{kind=link}