La Inteligencia Artificial está abriendo las puertas a nuevos paradigmas computacionales gracias a los avances en el diseño de modelos de Machine Learning o Deep Learning. Pero el entrenamiento de estos modelos, a su vez, precisa de sistemas computacionales con una potencia de procesamiento de datos progresivamente más elevada. Y aquí es donde entra en juego la compañía Cerebra y su procesador con tamaño de Tablet, que es, de hecho, el procesador más grande del mundo en tamaño.
La empresa Cerebras es joven: se fundó en 2016 en Sunnyvale, California, en pleno Silicon Valley, a partir de la iniciativa de cinco “ex” de la empresa SeaMicro, adquirida por AMD en 2015 en el contexto de su expansión en el segmento de las soluciones para HPC y centros de datos y servidores. La idea de estos cinco profesionales en diseño de chips, era la de crear una solución para el entrenamiento de modelos de IA para algoritmos de aprendizaje profundo (Deep Learning).
Solo tardaron tres años en anunciar su primer Wafer-Scale Engine o WSE-1. Cuando hablan de Wafer-Scale, se refieren a que el procesador que estaban diseñando ocuparía una oblea completa. Tradicionalmente, de una oblea de 300 mm de diámetro (30 cm) se obtienen cientos de procesadores, o decenas de ellos, dependiendo del tamaño de los chips. Pero si hablamos de Wafer-Scale Engine, tenemos que de una oblea se obtiene un único procesador.
Estos cinco profesionales identificaron una necesidad en aquel momento: diseñar un procesador específico para cargas relacionadas con la Inteligencia artificial desde la perspectiva del entrenamiento de los modelos de Deep Learning. Estas cargas se diferencian de las cargas convencionales en varios aspectos: por un lado, la prioridad es la velocidad en el movimiento de datos, memoria que esté “cerca” de los cores y los cores trabajan de forma individual sobre los datos. Los modelos de Deep Learning e inferencia cuentan con cientos de millones o incluso miles de millones de parámetros.
En principio, la arquitectura de los procesadores de las tarjetas gráficas podría parecer que se adecua a estas premisas. Y, de hecho, las GPUs en sus variantes profesionales para centros de datos y servidores, cuentan con arquitecturas en las que encontramos incluso miles de cores en un mismo chip, con memorias que están “cerca” de los cores como las memorias HBM2. Cuando decimos “cerca”, nos referimos a que los circuitos electrónicos que conforman los buses que interconectan la memoria con los cores están en el mismo chip o en chips muy próximos a los cores.
Con todo, estos profesionales fundadores de Cerebras querían ir más allá de las soluciones existentes. Los chips de las GPUs actuales como las de AMD o NVIDIA son especialmente “grandes” en dimensiones, todo sea dicho. Mucho más grandes que los procesadores de propósito general de Intel o AMD. Por ejemplo, el chip NVIDIA GA102 tiene un tamaño de 2,6 x 2,4 cm o 628 mm2 con 28.300 millones de transistores. Un procesador Intel Tiger Lake tiene un tamaño de unos 150 mm2 o 1,36 x 1,07 cm. La GPU Tesla A100 tiene 54.000 millones de transistores (54 millardos o 0,054 billones) y 826 mm2 de tamaño con tecnología de 7 nm.
Los ingenieros de Cerebras, apostaron por diseñar un chip con un tamaño tan grande como pudiera fabricarse en una oblea de silicio. La primera versión del WSE de Cerebras tenía 400.000 cores, 1,2 billones de transistores (1.200 millardos o 1.200.000 millones) y 18 GB de memoria en el propio chip. En abril de este año, Cerebras anunció el WSE-2, con tecnología de 7 nm de TSMC, con 850.000 cores, 2,6 billones de transistores y 40 GB de memoria SRAM en el propio chip. El tamaño es de 46.225 mm2. Además, la memoria externa puede ser de nada menos que de 2,4 PetaBytes con una interconexión con el chip tan rápida como las conexiones dentro del propio silicio. El ancho de banda de memoria es de 20 PB/s, que es 9.800x mejor que el de las GPUs más avanzadas. El tamaño es, básicamente, el de una tableta.
En cuanto al consumo, tenemos nada menos que 15 kW. A modo de comparación, la GPU NVIDIA A100 consume 400W. El precio, a la vista de lo que costaba la primera versión, que eran nada menos que más de dos millones de dólares, solo está al alcance de grandes empresas, Universidades o incluso estados. Y eso es solo el chip: Cerebras también ofrece sistemas completos construidos alrededor del chip, como el CS-2 para el WSE-2, donde encontramos una conectividad de red con un ancho de banda de nada menos que 12 conexiones de red 100 GbE para un total de 1,2 Tbps.
La virtud y elemento diferenciador del chip WSE-2 de Cerebras es su capacidad para mover datos a velocidad suficiente para procesar miles de millones (120 billones en concreto) de parámetros, lo cual permite trabajar con redes neuronales de tipo “brain-scale”, comparables al cerebro en cuanto a conexiones.
Lo que llama la atención es el yield que consigue Cerebra junto con TSMC en la fabricación de este chip. El yield (aprovechamiento en inglés) hace referencia a cuántos chips válidos aptos para la comercialización se obtienen a partir de una oblea. Cuando tenemos miles de millones de transistores en un chip, los fallos en los procesos litográficos pueden hacer que un chip sea defectuoso completamente, o partes de él no puedan usarse. Los fabricantes pueden, en ocasiones, activar o desactivar elementos de los chips en estos casos. En el chip WSE-2, el yield es del 100%. Es cierto que el nodo de 7 nm de TSMC está muy avanzado y maduro, pero no deja de ser llamativo que todos los chips fabricados puedan usarse sin problemas cuando tenemos 1.2 billones de transistores en juego.
El chip WSE-2 es solo una de las piezas del rompecabezas: Cerebras ofrece a los clientes los sistemas CS construidos alrededor del chip, más memoria ultra rápida adicional más conectividad de red con hasta 1,2 Tbps de ancho de banda agregado. LA clave está en proporcionar datos al sistema a una velocidad suficiente como para que el chip haga su trabajo sin tener que “esperar” por los datos más allá de las especificaciones del hardware.
El sistema CS-2 basado en el WSE-2 tiene un formato físico de 15 RU y ofrece rendimiento propio de un clúster de sistemas basados en GPUs en un único sistema. Además, se pueden combinar varios sistemas CS-2 en un clúster para ofrecer rendimiento a escala de centro de datos a partir de un clúster de sistemas CS-2, con lo que se obtiene un notable ahorro de espacio y consumo energético. Es cierto que un sistema CS-2 consume 23 kW, pero es menos que un clúster de GPUs. Y varios sistemas CS-2 consumen menos que un centro de datos. La refrigeración es líquida para los sistemas CS-2 y todos los elementos están diseñados para que el procesador trabaje al máximo de su potencial, con estabilidad y eficiencia.
Además del chip y el sistema, Cerebras ofrece a los clientes herramientas de software para “llevar” sus modelos de Deep Learning e inferencia al chip WSE-2 para procesar los parámetros de los modelos de IA. El sistema CS-2 es compatible con las frameworks de Machine Learning existentes, como TensorFlow, PyTorch o incluso en lenguajes como C o Python. El “alma” del CS-2 podría ser el compilador Cerebras Graph Compiler o CGC.
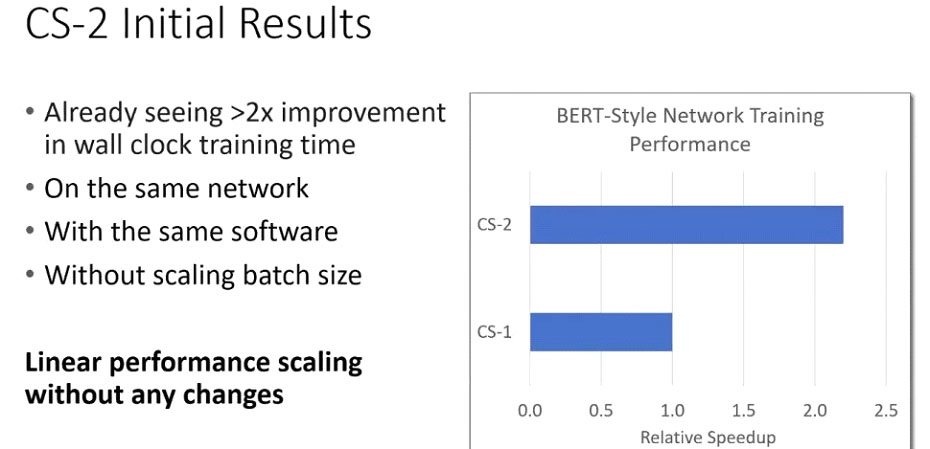
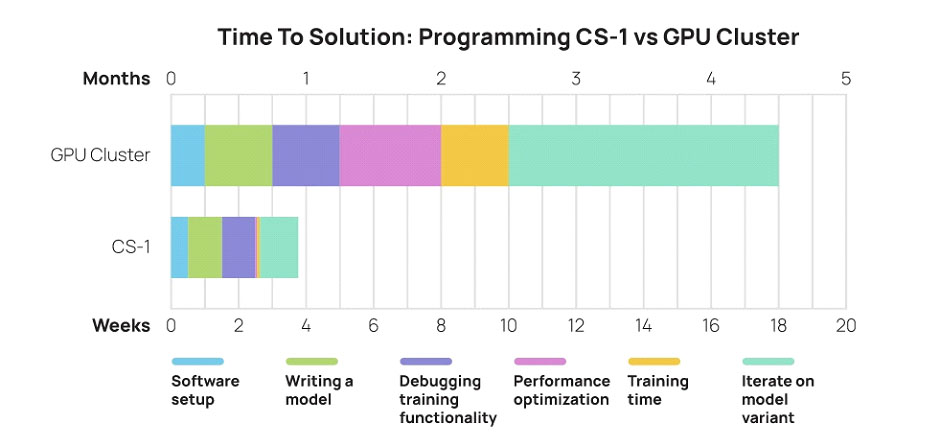
Tras convertir los modelos de Deep Learning en “ejecutables” para CS-2 usando el compilador, se obtiene código compatible con el procesador. Es ahí donde entra en juego el rendimiento del WSE-2. Las ganancias en tiempo y en el incremento de la complejidad de los modelos de IA son las que diferencian a Cerebras de otras compañías: al no tener que “trocear” los cálculos para “clusterizarlos” a través de decenas o centenares o miles de servidores con GPUs, el procesamiento de los modelos se acelera enormemente como se puede ver en la infografía.
Cerebras también puede “clusterizar” el procesamiento de modelos de IA a través de varios sistemas CS-2 organizados como clúster, por supuesto. Estos clústeres suponen incrementar la capacidad de procesamiento prácticamente de un modo exponencial frente a soluciones tradicionales basadas en paralelismo de GPU.
Los campos de aplicación de la solución de Cerebras son diversos, aunque no hay sorpresas: aquellos en los que ya se usa la IA para desarrollar servicios y herramientas que permitan avanzar en los diferentes campos y áreas de actividad, se beneficiarán de esta tecnología siempre y cuando se trate de modelos de IA complejos.
Hablamos de campos como la salud y la medicina, así como las industrias farmacéuticas. En redes sociales y búsquedas, clasificación de texto o plataformas de recomendación se emplean modelos complejos y se manejan ingentes cantidades de datos. Las administraciones públicas también son clientes potenciales para análisis de imagen y vídeo, así como para traducciones automáticas, mantenimiento predictivo, etcétera. En finanzas y seguros, investigación científica o el sector de la energía y el petróleo, la IA también se utiliza de forma generalizada.
Estos sistemas, se usan de forma complementaria para los centros de datos y servidores convencionales y conviven generalmente con estos últimos. Allí donde se necesite entrenar o modelar un sistema de IA a gran escala, los sistemas de Cerebras están justificados para contar con sistemas dedicados exclusivamente para la IA. En caso contrario, habría que dedicar sistemas convencionales para los cálculos de modelos, consumiendo mucho más tiempo y recursos que los sistemas CS-2, lo cual redunda en una doble pérdida: de tiempo, al necesitar mucho más que los sistemas basados en el WSE-2 y de recursos al no poder dedicar sistemas de propósito general o GPUs a otras tareas optimizadas para las CPUs y GPUs tradicionales.
Las ventajas de los sistemas de Cerebras parecen claras. Y la razón de ser de un chip con 1,2 billones de transistores también está más clara una vez que se comprenden un poco más los entresijos de la IA: la parte que más recursos consume en IA es la del diseño de los modelos de Deep Learning o inferencia y su entrenamiento. Cuantas más variables se usen para crear los modelos, más complejidad y mejores modelos se pueden crear, pero con GPUs, el entrenamiento de los modelos puede llegar a eternizarse, especialmente si hay que hacer modificaciones y revisiones en un proceso de refinamiento continuo. Tener todos los cores, memoria y conectividad de alta velocidad y baja latencia en un mismo chip es una ventaja frente a los clústeres de GPUs. Una ventaja que ahorra tiempo y abre las puertas al uso de modelos con un número de nodos comparable al que interviene en los procesos cerebrales. Nada menos.
Más información: Cerebras
La aplicación de confianza con la que más se entrometen los ciberdelincuentes es el Protocolo…
Un estudio de IFS, Boom e IDC revela que solamente un 19 % de las…
Para garantizar la privacidad, el 30 % se ha pasado a otra compañía durante el…
Check Point Software Technologies prevé que los avances en inteligencia artificial permitirán a pequeños grupos…
El 7 % de los internautas recurre a estas aplicaciones de forma habitual y cerca…
Le siguen otros profesionales como el gerente de gobernanza, el gestor de datos y el…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}