Nos encontramos en los albores de la era del Big Data. La información digital crece a un ritmo casi exponencial año tras año, algo que seguirá ocurriendo durante las próximas décadas de forma ineludible. Es un hecho que el ser humano está generando información nueva más rápidamente de la que se puede almacenar de forma eficiente.
Es cierto que se están desarrollando soportes de almacenamiento que ofrecen cada vez más capacidad y persistencia, pero actualmente la vida útil de dichos soportes (ópticos, cintas magnéticas, discos duros o memorias flash) es de unos 7 años, insuficiente para determinados ámbitos en los que se necesita almacenar información en largos periodos de tiempo por motivos de cumplimiento o simplemente porque esos datos pueden ser importantes en el futuro.
Aquí se incluyen los datos que se archivan para, probablemente, no ser utilizados nunca más, pero que es necesario mantenerlos en algún lugar. Se calcula que esta información supone el 70% del total que se genera, lo que se denomina información WORN (Write Once Read Never).
Habitualmente, el soporte utilizado son las unidades de cinta magnética: son económicas y se puede archivar mucha información en ellas. Pero el acceso a estos datos es secuencial y muy lento en comparación a otros soportes.
Además, cada cierto tiempo es necesario replicar toda esa información y mantenerse a una temperatura y humedad constantes, lo que supone un coste importante para las organizaciones.
La transformación digital que estamos viviendo necesita una revolución en materia de almacenamiento y la compañía francesa Biomemory está trabajando en un proyecto que podría desembocar en dicha revolución.
Ciertamente, existe un tipo de almacenamiento que no ha sido desarrollado por el hombre, pero que ha estado evolucionando a lo largo de 4.000 millones de años: el ADN.
Pues bien, Biomemory Labs (una spin-off de la Universidad de Sorbonne francesa que se creo el año pasado) está desarrollando una tecnología que tiene el potencial de sustituir los medios de almacenamiento tradicionales, reduciendo además su alto consumo energético. Esta tecnología es capaz de codificar y organizar los datos en moléculas de ADN de doble cadena, es decir, es capaz de replicar el ADN de forma sintética de tal forma que pueda almacenar cualquier tipo de información.
Se trata de la tecnología DNA Drive, que la compañía define como una estrategia de almacenamiento de datos en ADN biosegura y biocompatible con capacidad ilimitada.
La estabilidad del ADN supera a la de cualquier otro medio de forma aplastante. Lo demuestra la recuperación exacta del ADN de un mamut que vivió hace un millón de años, por ejemplo.
Su densidad también llega a ser espectacular. Según asegura Biomemory, es de 4,5×10 elevado a 20 bytes por gramo de ADN, es decir, se podrían almacenar 0,45 Zettabytes en un gramo de ADN.
Todos los datos digitales generados por la humanidad en 2019 (45 ZettaBytes) se podrían almacenar en 100 gramos de ADN.
Por otra parte, el ADN almacenado no necesita energía ya que las moléculas son totalmente estables en condiciones apropiadas.
Ya en 2012 se mostraron avances significativos a la hora de codificar datos en secuencias sintéticas de ADN “in-vitro” a través de una serie de algoritmos, pero existían diversas limitaciones como la baja densidad de almacenamiento o la lentitud a la hora de escribir o leer la información.
El acercamiento de Biomemory para superar esas limitaciones a la hora de almacenar información en el ADN se basa en utilizar procesos biológicos y las propiedades de los organismos vivos.
DNA Drive utiliza moléculas de ADN de doble cadena como soporte físico, compatibles con la manipulación in-vitro e in-vivo.
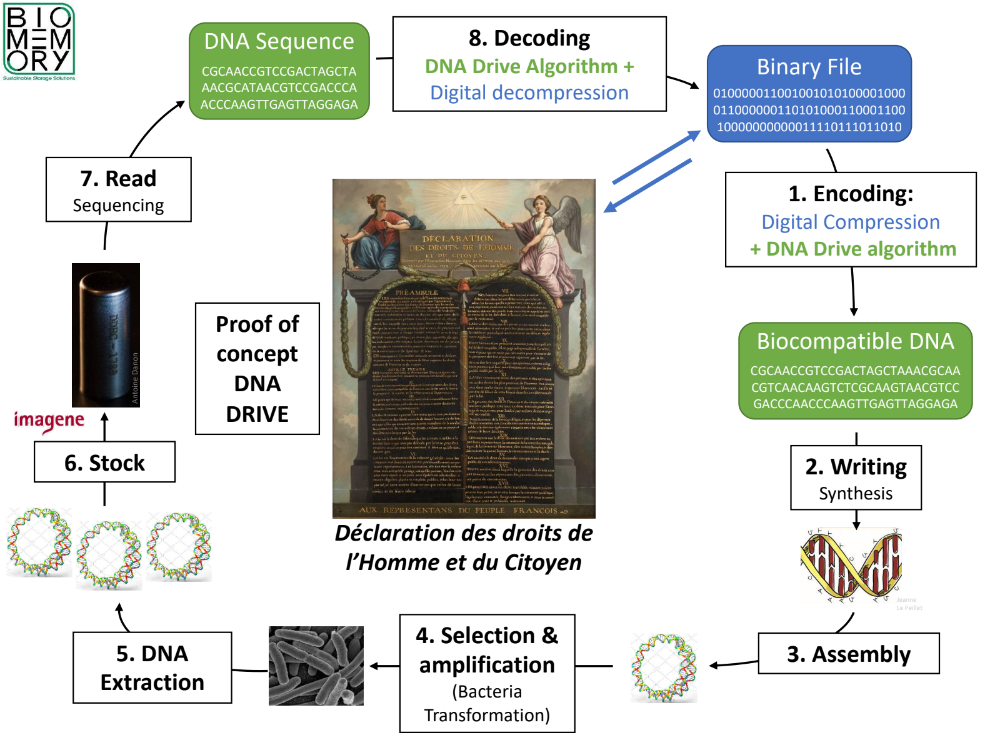
“Una vez que se han construido dichas moléculas se pueden introducir en organismos vivos para su posterior manipulación. Nuestra tecnología permite una organización física multi-escala que habilita el acceso aleatorio, facilita el ensamblaje tras la secuenciación y ofrece una capacidad ilimitada”, señalaba los responsables de Biomemory durante el pasado IT Press Tour (el evento de prensa donde tuvimos la oportunidad de conocer en detalle esta tecnología).
Sin querer entrar en detalles demasiado técnicos (el que escribe tiene conocimientos limitados en Biología), Biomemory ha desarrollado un algoritmo denominado RISE (Random In-Silico Evolution), capaz de codificar y ensamblar la información del estado binario (0 / 1) al estado cuaternario ( A / C / G / T ) característico de las secuencias de nucleótidos para asegurar la compatibilidad con el ADN.
La estructura de DNA Drive está compuesta por unidades de almacenamiento llamados sectores. Cada sector está compuesto por un bloque de datos de longitud ajustable donde la información es almacenada.
Biomemory cuenta con unidades ya en funcionamiento. De hecho, ha demostrado sus capacidades con la codificación de textos históricos basados en la revolución francesa: “La Déclaration des droits de l’homme et du citoyen” (1789) y “La Déclaration des droits de la femme et de la citoyenne” (Olympe de Gouges, 1791).
Ambos se encuentran ensamblados y almacenados en unas cápsulas metálicas denominadas DNAshell (en la imagen de portada), lo que asegurará su estabilidad durante cientos de años y su lectura con un 100% de fidelidad.
Biomemory admite que aún queda mucho camino por recorrer, sobre todo a la hora de codificar y almacenar la información. Es un proceso aún muy lento que hay que desarrollar para que algún día pueda ser viable como producto. Pero también indica que algo muy parecido ocurrió en la década de los 60 con la computación tradicional donde nadie habría apostado un céntimo por su desarrollo hasta lo que es en nuestros días.
¿Se convertirá DNA Drive en la siguiente gran revolución (y estándar) en el almacenamiento masivo de datos? Lo veremos en unos años.
Atlassian inaugura Team ’25 con IA para todos, seguridad cloud reforzada y alianzas estratégicas como…
Los excelentes resultados cosechados en los últimos años, con un crecimiento medio en España del…
La cifra es fruto de la acumulación protagonizada por diversa ubicaciones, incluyendo Madrid.
“Los clientes no deberían tener que elegir entre formatos abiertos y un rendimiento superior, o…
IDC advierte sobre el incremento de los aranceles por parte de Estados Unidos y sus…
Este hub incluye un módulo de innovación en ciberseguridad, que presentará las soluciones de Kaspersky…
{kind=link}
{kind=link}
{kind=link}
{kind=link}